Cuidados com a interação entre as variáveis preditoras
Você prefere o molho de ketchup ou shoyou?
Se alguém lhe fez essa pergunta, sua resposta provavelmente depende do que está comendo. Você provavelmente não mergulharia seu sushi em ketchup. E a maioria das pessoas não parece gostar de comer molho de soja com batatas fritas quentes.
Um erro comum ao usar ANOVA ou DOE para avaliar fatores
Técnicas de modelagem como ANOVA ou Planejamento de Experimentos (DOE) podem determinar se os fatores de interesse afetam um processo. Por exemplo, você pode querer avaliar como várias configurações de tempo e temperatura afetam a qualidade do produto. Ou você pode querer determinar quais fatores influenciam no tempo de processamento de um empréstimo, ou ma satisfação do cliente, ou na lucratividade.
Então você coleta dados sobre seus fatores de interesse, e agora está pronto para fazer sua análise. Este é o lugar onde muitas pessoas cometem o infeliz erro de olhar apenas para cada fator individualmente.
Além de considerar a forma como cada fator afeta sua variável de resposta, você também precisa avaliar a interação entre esses fatores e determinar se algum deles também é significativo. E assim como sua preferência por molho de ketchup versus molho de soja depende do que você está comendo, as configurações ótimas para um determinado fator dependerão das configurações do outro fator quando uma interação estiver presente.
Como avaliar e interpretar uma interação
Vamos usar um exemplo de perda de peso para ilustrar como podemos avaliar uma interação entre fatores. Estamos avaliando 2 dietas diferentes e 2 diferentes programas de exercícios: um focado em cardio e um focado musculação. Queremos determinar qual dará o maior resultado na perda de peso. Atribuímos aleatoriamente os participantes para a dieta A ou B e para o regime de treinamento cardio ou musculação e, em seguida, registramos a quantidade de peso perdida após 1 mês.
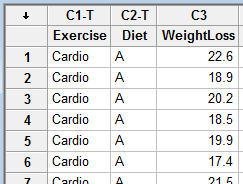
Aqui está um extrato dos dados:
Para avaliar o efeito de múltiplos fatores em uma resposta contínua, podemos usar Stat> ANOVA> Modelo Linear Geral no Minitab, que produz os seguintes resultados para nossos dados:
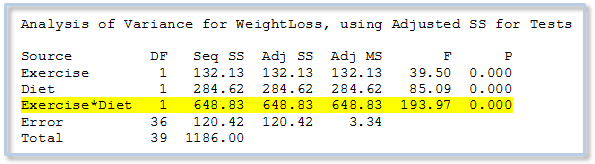
Podemos ver que o p-valor para a interação Exercício * Dieta é 0.000. Como esse p-valor tão pequeno, podemos concluir que existe uma interação significativa entre Exercício e Dieta. Então, qual dieta é melhor? Nossos dados sugerem que é como perguntar "ketchup ou molho de soja?" A resposta é: "Depende".
Uma vez que a interação Exercício * Dieta é significativa, vamos usar um gráfico de interação para examinar de perto:
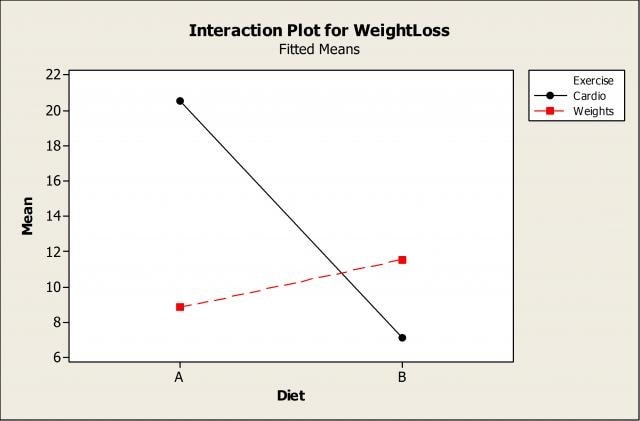
Para os participantes que usam o programa cardio (mostrado em preto), podemos ver que a dieta A é melhor e resulta em maior perda de peso. No entanto, se você estiver seguindo o regime de treinamento de peso (mostrado em vermelho), a dieta B resulta em maior perda de peso do que A.
O Perigo de Ignorar Interações entre Fatores
Suponha que essa interação não esteja em nosso radar e, em vez disso, foquemos apenas nos efeitos individuais principais e o seu impacto na perda de peso:
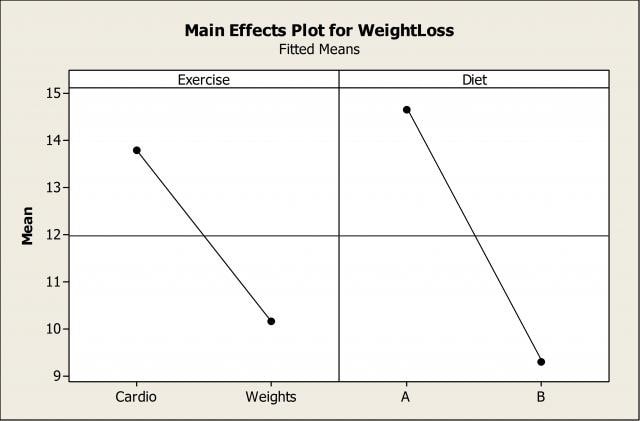
Com base nesse enredo, concluiremos incorretamente que a dieta A é melhor do que B. Como vimos do enredo de interação, o que só é verdade se olharmos para o grupo de cardio.
Claramente, sempre precisamos avaliar interações ao analisar múltiplos fatores. Se você não fizer isso, corre o risco de tirar conclusões incorretas ... e você pode apenas obter ketchup para colocar em seu rolo de sushi.
Cuidados para não “super ajustar” os modelos de regressão
Na análise de regressão, ajustar demais um modelo é um problema real. Um modelo sobreajuste pode fazer com que os coeficientes de regressão, p-valores e R-quadrados sejam enganadores. Nessa sessão explicar-se-á o que é um modelo de regressão sobreajuste e a como detectar e evitar esse problema.
Um modelo de regressão sobreajuste que é muito complicado e que foi ajustado apenas para o seu conjunto de dados. Quando isso acontece, o modelo de regressão torna-se adaptado para ajustar as peculiaridades e o ruído aleatório em sua amostra específica em vez de refletir a população em geral. Se você retirasse outra amostra de dados, teria suas próprias peculiaridades, e seu modelo sobreajuste original provavelmente não caberia aos novos dados.
Em vez disso, temos que elaborar um modelo que se aproxime do verdadeiro para toda a população. Nosso modelo não deve apenas caber na amostra atual, mas também nas novas amostras.
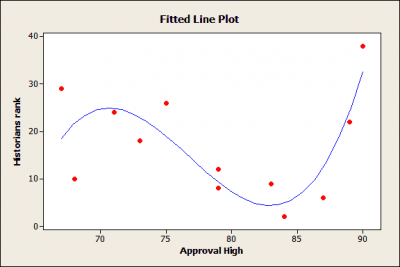
O gráfico de linha ajustado ilustra os perigos de super ajustar modelos de regressão. Este modelo parece explicar muito da variação na variável de resposta. No entanto, o modelo é muito complexo para os dados da amostra. Na população geral, não existe uma relação real entre a variável preditora e a variável resposta.
Fundamentos de Estatísticas Inferenciais
Para entender como o super-ajuste causa problemas, precisamos voltar ao básico sobre as estatísticas inferenciais. O objetivo geral das estatísticas inferenciais é tirar conclusões sobre uma população maior de uma amostra aleatória. As estatísticas inferenciais usam os dados da amostra para fornecer:
- Estimativas imparciais de propriedades e relacionamentos dentro da população.
- Testes de hipóteses que avaliem declarações sobre toda a população.
Um conceito importante nas estatísticas inferenciais é que a quantidade de informações que você pode aprender sobre uma população é limitada pelo tamanho da amostra. Quanto mais quiser aprender, maior será o seu tamanho de amostra.
Você provavelmente entende esse conceito intuitivamente, mas aqui está um exemplo. Se você tiver um tamanho de amostra de 20 e quiser estimar uma média de população, provavelmente está em boa forma. No entanto, se você quiser estimar médias de duas populações usando o mesmo tamanho total da amostra, de repente isso pode dar errado. Se você aumentar isso para a média de três populações, isso começa a parecer muito ruim.
A qualidade dos resultados piora quando você tenta aprender muito com uma amostra. À medida que o número de observações por parâmetro diminui no exemplo acima (20, 10, 6.7, etc.), as estimativas tornam-se mais erráticas e uma nova amostra tem menos probabilidade de reproduzi-las.
Aplicando esses conceitos para sobreajustar modelos de regressão
De forma semelhante, sobre ajustar um modelo de regressão acontece quando você tenta estimar muitos parâmetros de uma população com uma amostra que é muito pequena. A análise de regressão usa uma amostra para estimar os valores dos coeficientes para todos os termos da equação. O tamanho da amostra limita o número de termos que você pode incluir com segurança antes de começar a superar o modelo. A quantidade de termos no modelo inclui todos os preditores, efeitos de interação e termos de polinômios (para modelar a curvatura).
Maiores tamanhos de amostra permitem especificar modelos mais complexos. Para resultados confiáveis, o tamanho da amostra deve ser grande o suficiente para suportar o nível de complexidade exigido pela pergunta da sua pesquisa. Se seu tamanho de amostra não for grande o suficiente, você não poderá ajustar um modelo que se aproxime adequadamente do modelo verdadeiro para sua variável de resposta. Você não poderá confiar nos resultados.
Assim como o exemplo com múltiplos meios, você deve ter um número suficiente de observações para cada termo em um modelo de regressão. Estudos de simulação mostram que uma boa regra é ter 10-15 observações por período em regressão linear múltipla.
Por exemplo, se seu modelo contém duas variáveis preditoras e um termo de interação, você precisará de 30 a 45 observações. No entanto, se o tamanho do efeito for pequeno ou a multicolinearidade elevada, você precisará de mais observações por período.
Como detectar e evitar modelos com sobreajuste
A validação cruzada pode detectar modelos com sobreajuste, determinando o quão bem o seu modelo se generaliza para outros conjuntos de dados, particionando seus dados. Este processo ajuda você a avaliar o quão bem o modelo se adapta a novas observações que não foram usadas no processo de estimativa do modelo.
O software estatístico Minitab fornece uma excelente solução de validação cruzada para modelos lineares calculando o R² previsto. Esta estatística é uma forma de validação cruzada que não exige que você colete uma amostra separada. Em vez disso, o Minitab calcula o R² previsto, eliminando sistematicamente cada observação do conjunto de dados, estimando a equação de regressão e determinando como o modelo prediz a observação removida.
Se o modelo faz um mau trabalho ao prever as observações removidas, isso indica que o modelo provavelmente é adaptado aos pontos de dados específicos que estão incluídos na amostra e não generalizáveis fora da amostra.
Para evitar o sobre ajuste do seu modelo em primeiro lugar, colete uma amostra suficientemente grande para que você possa incluir com segurança todos os preditores, efeitos de interação e polinomial lógicos que sua variável de resposta requer. O processo científico envolve muita pesquisa antes mesmo de começar a coletar dados. Você deve identificar as variáveis importantes, o modelo que você provavelmente especificará e usar essas informações para estimar um bom tamanho de amostra.
Quer aprender mais sobre como avaliar e interpretar uma interação? Faça nossos cursos de Green Belt e Black Belt! Aprofunde e aplique seus conhecimentos!